
GitHub Copilot 是 GitHub 去年 6 月推出的人工智能模型,这是一个利用机器学习技术为开发者提供代码建议和代码补全的工具,能够帮助开发者更快完成编程任务。但由于 GitHub Copilot 训练使用的数据集,以及该工具如今成为了一款向开发者收费的商业性产品,GitHub Copilot 也引发了一些争议。
那有没有一个能够替代 GitHub Copilot 的工具呢?
近日美国纽约大学计算机科学和工程系助理教授 Brendan Dolan-Gavitt 开源了一个名为 FauxPilot 的项目,根据介绍,这是 GitHub Copilot 的替代品,能够在本地运行并且不会上传用户的数据,如果开发者使用的是自己训练的 AI 模型,也无需再担心生成代码的许可问题。
GitHub Copilot 依赖于 OpenAI Codex,后者是一个基于 GPT-3 的自然语言转代码系统,使用了存储在 GitHub 上的 “数十亿行公共代码” 进行训练。而 FauxPilot 并没有使用 Codex,为了方便开发者使用它依赖了 Salesforce 的 CodeGen 模型,CodeGen 同样也是使用公共开源代码进行训练的。
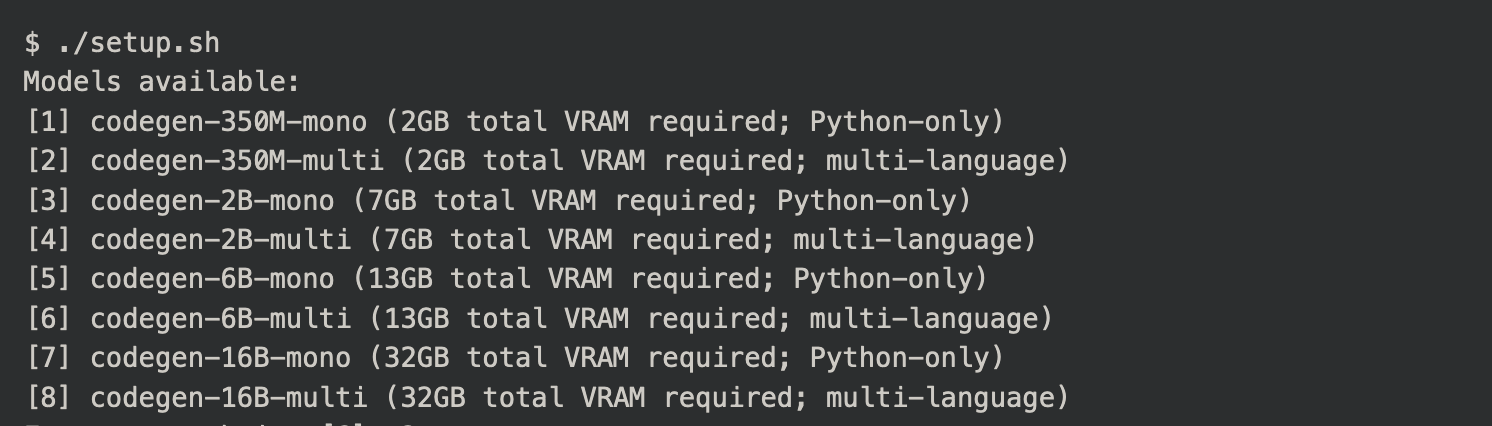
目前 Salesforce CodeGen 提供了 3.5 亿、20 亿、60 亿 和 160 亿参数的模型,但在 FauxPilot 这边只看到 3.5 亿、60 亿和 160 亿的模型,暂时没有 20 亿模型可用,这就对训练模型需要使用的 GPU 提出了较高的要求。因为 3.5 亿参数的模型仅需要 2GB VRAM;而稍高一个档次的 60 亿参数模型所需要的 VRAM 就大幅上涨到了 13GB,这就需要至少 RTX 3090 的显卡才能跑,就更不用说 160 亿的模型了。
由于 CodeGen 模型同样是通过公共代码训练的,因此给出的代码建议可能仍然存在版权 / 许可方面的问题。开发者 Dolan-Gavitt 表示,有足够计算能力的公司或开发者可以使用自己专有的代码库或使用特定协议的开源代码库(如只含 GPL 协议的代码仓库)训练模型,将训练好的模型导入 FauxPilot 即可正常使用,这样也无需再担心产生的代码会有许可问题了。这就是 FauxPilot 可以在本地运行的好处,它也能够为企业提供一种在内部运行人工智能辅助软件的方式。
FauxPilot 的另一个特点是对于隐私方面的考虑,它不会读取公司或开发者编写的代码,也不会将这些信息共享给第三方。
FauxPilot 在 GitHub 上的地址如下:https://github.com/moyix/fauxpilot
简介
这是一个本地托管版本的 GitHub Copilot。它在英伟达的 Triton 推理服务器中使用了 SalesForce CodeGen 模型和 FasterTransformer 后端。
前提条件
- Docker
- docker-compose >= 1.28
- 一台计算能力大于 7.0 的英伟达 GPU,以及足够的 VRAM 来运行你想要的模型
- nvidia-docker
- curl 和 zstd,用于下载和解包模型
Copilot 插件
你可以配置官方 VSCode Copilot 插件来使用你的本地服务器。只要编辑你的 settings.json 来添加。
"github.copilot.advanced": {
"debug.overrideEngine": "codegen",
"debug.testOverrideProxyUrl": "http://localhost:5000",
"debug.overrideProxyUrl": "http://localhost:5000"
}
设置
运行设置脚本以选择要使用的模型。 这将从 Huggingface 下载模型,然后将其转换为与 FasterTransformer 一起使用。
$ ./setup.sh
Models available:
[1] codegen-350M-mono (2GB total VRAM required; Python-only)
[2] codegen-350M-multi (2GB total VRAM required; multi-language)
[3] codegen-2B-mono (7GB total VRAM required; Python-only)
[4] codegen-2B-multi (7GB total VRAM required; multi-language)
[5] codegen-6B-mono (13GB total VRAM required; Python-only)
[6] codegen-6B-multi (13GB total VRAM required; multi-language)
[7] codegen-16B-mono (32GB total VRAM required; Python-only)
[8] codegen-16B-multi (32GB total VRAM required; multi-language)
Enter your choice [6]: 2
Enter number of GPUs [1]: 1
Where do you want to save the model [/home/moyix/git/fauxpilot/models]? /fastdata/mymodels
Downloading and converting the model, this will take a while...
Converting model codegen-350M-multi with 1 GPUs
Loading CodeGen model
Downloading config.json: 100%|██████████| 996/996 [00:00<00:00, 1.25MB/s]
Downloading pytorch_model.bin: 100%|██████████| 760M/760M [00:11<00:00, 68.3MB/s]
Creating empty GPTJ model
Converting...
Conversion complete.
Saving model to codegen-350M-multi-hf...
=============== Argument ===============
saved_dir: /models/codegen-350M-multi-1gpu/fastertransformer/1
in_file: codegen-350M-multi-hf
trained_gpu_num: 1
infer_gpu_num: 1
processes: 4
weight_data_type: fp32
========================================
transformer.wte.weight
transformer.h.0.ln_1.weight
[... more conversion output trimmed ...]
transformer.ln_f.weight
transformer.ln_f.bias
lm_head.weight
lm_head.bias
Done! Now run ./launch.sh to start the FauxPilot server.
FauxPilot
This is an attempt to build a locally hosted version of GitHub Copilot. It uses the SalesForce CodeGen models inside of NVIDIA’s Triton Inference Server with the FasterTransformer backend.
Prerequisites
You’ll need:
- Docker
docker-compose>= 1.28- An NVIDIA GPU with Compute Capability >= 7.0 and enough VRAM to run the model you want.
- nvidia-docker
curlandzstdfor downloading and unpacking the models.
Support and Warranty
lmao
Setup
Run the setup script to choose a model to use. This will download the model from Huggingface and then convert it for use with FasterTransformer.
$ ./setup.sh
Models available:
[1] codegen-350M-mono (2GB total VRAM required; Python-only)
[2] codegen-350M-multi (2GB total VRAM required; multi-language)
[3] codegen-2B-mono (7GB total VRAM required; Python-only)
[4] codegen-2B-multi (7GB total VRAM required; multi-language)
[5] codegen-6B-mono (13GB total VRAM required; Python-only)
[6] codegen-6B-multi (13GB total VRAM required; multi-language)
[7] codegen-16B-mono (32GB total VRAM required; Python-only)
[8] codegen-16B-multi (32GB total VRAM required; multi-language)
Enter your choice [6]: 2
Enter number of GPUs [1]: 1
Where do you want to save the model [/home/moyix/git/fauxpilot/models]? /fastdata/mymodels
Downloading and converting the model, this will take a while...
Converting model codegen-350M-multi with 1 GPUs
Loading CodeGen model
Downloading config.json: 100%|██████████| 996/996 [00:00<00:00, 1.25MB/s]
Downloading pytorch_model.bin: 100%|██████████| 760M/760M [00:11<00:00, 68.3MB/s]
Creating empty GPTJ model
Converting...
Conversion complete.
Saving model to codegen-350M-multi-hf...
=============== Argument ===============
saved_dir: /models/codegen-350M-multi-1gpu/fastertransformer/1
in_file: codegen-350M-multi-hf
trained_gpu_num: 1
infer_gpu_num: 1
processes: 4
weight_data_type: fp32
========================================
transformer.wte.weight
transformer.h.0.ln_1.weight
[... more conversion output trimmed ...]
transformer.ln_f.weight
transformer.ln_f.bias
lm_head.weight
lm_head.bias
Done! Now run ./launch.sh to start the FauxPilot server.
Then you can just run ./launch.sh:
$ ./launch.sh
[+] Running 2/0
⠿ Container fauxpilot-triton-1 Created 0.0s
⠿ Container fauxpilot-copilot_proxy-1 Created 0.0s
Attaching to fauxpilot-copilot_proxy-1, fauxpilot-triton-1
fauxpilot-triton-1 |
fauxpilot-triton-1 | =============================
fauxpilot-triton-1 | == Triton Inference Server ==
fauxpilot-triton-1 | =============================
fauxpilot-triton-1 |
fauxpilot-triton-1 | NVIDIA Release 22.06 (build 39726160)
fauxpilot-triton-1 | Triton Server Version 2.23.0
fauxpilot-triton-1 |
fauxpilot-triton-1 | Copyright (c) 2018-2022, NVIDIA CORPORATION & AFFILIATES. All rights reserved.
fauxpilot-triton-1 |
fauxpilot-triton-1 | Various files include modifications (c) NVIDIA CORPORATION & AFFILIATES. All rights reserved.
fauxpilot-triton-1 |
fauxpilot-triton-1 | This container image and its contents are governed by the NVIDIA Deep Learning Container License.
fauxpilot-triton-1 | By pulling and using the container, you accept the terms and conditions of this license:
fauxpilot-triton-1 | https://developer.nvidia.com/ngc/nvidia-deep-learning-container-license
fauxpilot-copilot_proxy-1 | WARNING: This is a development server. Do not use it in a production deployment. Use a production WSGI server instead.
fauxpilot-copilot_proxy-1 | * Debug mode: off
fauxpilot-copilot_proxy-1 | * Running on all addresses (0.0.0.0)
fauxpilot-copilot_proxy-1 | WARNING: This is a development server. Do not use it in a production deployment.
fauxpilot-copilot_proxy-1 | * Running on http://127.0.0.1:5000
fauxpilot-copilot_proxy-1 | * Running on http://172.18.0.3:5000 (Press CTRL+C to quit)
fauxpilot-triton-1 |
fauxpilot-triton-1 | ERROR: This container was built for NVIDIA Driver Release 515.48 or later, but
fauxpilot-triton-1 | version was detected and compatibility mode is UNAVAILABLE.
fauxpilot-triton-1 |
fauxpilot-triton-1 | [[]]
fauxpilot-triton-1 |
fauxpilot-triton-1 | I0803 01:51:02.690042 93 pinned_memory_manager.cc:240] Pinned memory pool is created at '0x7f6104000000' with size 268435456
fauxpilot-triton-1 | I0803 01:51:02.690461 93 cuda_memory_manager.cc:105] CUDA memory pool is created on device 0 with size 67108864
fauxpilot-triton-1 | I0803 01:51:02.692434 93 model_repository_manager.cc:1191] loading: fastertransformer:1
fauxpilot-triton-1 | I0803 01:51:02.936798 93 libfastertransformer.cc:1226] TRITONBACKEND_Initialize: fastertransformer
fauxpilot-triton-1 | I0803 01:51:02.936818 93 libfastertransformer.cc:1236] Triton TRITONBACKEND API version: 1.10
fauxpilot-triton-1 | I0803 01:51:02.936821 93 libfastertransformer.cc:1242] 'fastertransformer' TRITONBACKEND API version: 1.10
fauxpilot-triton-1 | I0803 01:51:02.936850 93 libfastertransformer.cc:1274] TRITONBACKEND_ModelInitialize: fastertransformer (version 1)
fauxpilot-triton-1 | W0803 01:51:02.937855 93 libfastertransformer.cc:149] model configuration:
fauxpilot-triton-1 | {
[... lots more output trimmed ...]
fauxpilot-triton-1 | I0803 01:51:04.711929 93 libfastertransformer.cc:321] After Loading Model:
fauxpilot-triton-1 | I0803 01:51:04.712427 93 libfastertransformer.cc:537] Model instance is created on GPU NVIDIA RTX A6000
fauxpilot-triton-1 | I0803 01:51:04.712694 93 model_repository_manager.cc:1345] successfully loaded 'fastertransformer' version 1
fauxpilot-triton-1 | I0803 01:51:04.712841 93 server.cc:556]
fauxpilot-triton-1 | +------------------+------+
fauxpilot-triton-1 | | Repository Agent | Path |
fauxpilot-triton-1 | +------------------+------+
fauxpilot-triton-1 | +------------------+------+
fauxpilot-triton-1 |
fauxpilot-triton-1 | I0803 01:51:04.712916 93 server.cc:583]
fauxpilot-triton-1 | +-------------------+-----------------------------------------------------------------------------+----------------------------------------------------------------------------------------------------------------------------------------------------------------+
fauxpilot-triton-1 | | Backend | Path| Config |
fauxpilot-triton-1 | +-------------------+-----------------------------------------------------------------------------+----------------------------------------------------------------------------------------------------------------------------------------------------------------+
fauxpilot-triton-1 | | fastertransformer | /opt/tritonserver/backends/fastertransformer/libtriton_fastertransformer.so | {"cmdline":{"auto-complete-config":"false","min-compute-capability":"6.000000","backend-directory":"/opt/tritonserver/backends","default-max-batch-size":"4"}} |
fauxpilot-triton-1 | +-------------------+-----------------------------------------------------------------------------+----------------------------------------------------------------------------------------------------------------------------------------------------------------+
fauxpilot-triton-1 |
fauxpilot-triton-1 | I0803 01:51:04.712959 93 server.cc:626]
fauxpilot-triton-1 | +-------------------+---------+--------+
fauxpilot-triton-1 | | Model | Version | Status |
fauxpilot-triton-1 | +-------------------+---------+--------+
fauxpilot-triton-1 | | fastertransformer | 1 | READY |
fauxpilot-triton-1 | +-------------------+---------+--------+
fauxpilot-triton-1 |
fauxpilot-triton-1 | I0803 01:51:04.738989 93 metrics.cc:650] Collecting metrics for GPU 0: NVIDIA RTX A6000
fauxpilot-triton-1 | I0803 01:51:04.739373 93 tritonserver.cc:2159]
fauxpilot-triton-1 | +----------------------------------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
fauxpilot-triton-1 | | Option | Value |
fauxpilot-triton-1 | +----------------------------------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
fauxpilot-triton-1 | | server_id | triton
|
fauxpilot-triton-1 | | server_version | 2.23.0 |
fauxpilot-triton-1 | | server_extensions | classification sequence model_repository model_repository(unload_dependents) schedule_policy model_configuration system_shared_memory cuda_shared_memory binary_tensor_data statistics trace |
fauxpilot-triton-1 | | model_repository_path[0] | /model |
fauxpilot-triton-1 | | model_control_mode | MODE_NONE |
fauxpilot-triton-1 | | strict_model_config | 1 |
fauxpilot-triton-1 | | rate_limit | OFF |
fauxpilot-triton-1 | | pinned_memory_pool_byte_size | 268435456 |
fauxpilot-triton-1 | | cuda_memory_pool_byte_size{0} | 67108864 |
fauxpilot-triton-1 | | response_cache_byte_size | 0 |
fauxpilot-triton-1 | | min_supported_compute_capability | 6.0 |
fauxpilot-triton-1 | | strict_readiness | 1 |
fauxpilot-triton-1 | | exit_timeout | 30 |
fauxpilot-triton-1 | +----------------------------------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
fauxpilot-triton-1 |
fauxpilot-triton-1 | I0803 01:51:04.740423 93 grpc_server.cc:4587] Started GRPCInferenceService at 0.0.0.0:8001
fauxpilot-triton-1 | I0803 01:51:04.740608 93 http_server.cc:3303] Started HTTPService at 0.0.0.0:8000
fauxpilot-triton-1 | I0803 01:51:04.781561 93 http_server.cc:178] Started Metrics Service at 0.0.0.0:8002
API
Once everything is up and running, you should have a server listening for requests on http://localhost:5000. You can now talk to it using the standard OpenAIAPI (although the full API isn’t implemented yet). For example, from Python, using the OpenAI Python bindings:
$ ipython
Python 3.8.10 (default, Mar 15 2022, 12:22:08)
Type 'copyright', 'credits' or 'license' for more information
IPython 8.2.0 -- An enhanced Interactive Python. Type '?' for help.
In [1]: import openai
In [2]: openai.api_key = 'dummy'
In [3]: openai.api_base = 'http://127.0.0.1:5000/v1'
In [4]: result = openai.Completion.create(engine='codegen', prompt='def hello', max_tokens=16, temperature=0.1, stop=["\n\n"])
In [5]: result
Out[5]:
<OpenAIObject text_completion id=cmpl-6hqu8Rcaq25078IHNJNVooU4xLY6w at 0x7f602c3d2f40> JSON: {
"choices": [
{
"finish_reason": "stop",
"index": 0,
"logprobs": null,
"text": "() {\n return \"Hello, World!\";\n}"
}
],
"created": 1659492191,
"id": "cmpl-6hqu8Rcaq25078IHNJNVooU4xLY6w",
"model": "codegen",
"object": "text_completion",
"usage": {
"completion_tokens": 15,
"prompt_tokens": 2,
"total_tokens": 17
}
}
Copilot Plugin
Perhaps more excitingly, you can configure the official VSCode Copilot plugin to use your local server. Just edit your settings.json to add:
"github.copilot.advanced": {
"debug.overrideEngine": "codegen",
"debug.testOverrideProxyUrl": "http://localhost:5000",
"debug.overrideProxyUrl": "http://localhost:5000"
}
And you should be able to use Copilot with your own locally hosted suggestions! Of course, probably a lot of stuff is subtly broken. In particular, the probabilities returned by the server are partly fake. Fixing this would require changing FasterTransformer so that it can return log-probabilities for the top k tokens rather that just the chosen token.
Have fun!