
余弦相似度
余弦相似度 (Cosine Similarity) 通过计算两个向量的夹角余弦值来评估他们的相似度。将向量根据坐标值,绘制到向量空间中,求得他们的夹角,并得出夹角对应的余弦值,此余弦值就可以用来表征这两个向量的相似性。夹角越小,余弦值越接近于1,它们的方向越吻合,则越相似。
- 余弦定理
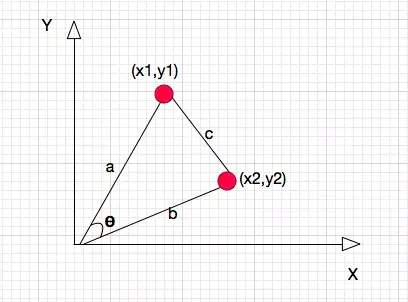
以二维空间为例,上图的a和b是两个向量,我们要计算它们的夹角θ。余弦定理告诉我们,可以用下面的公式求得:
- 三角形的余弦公式
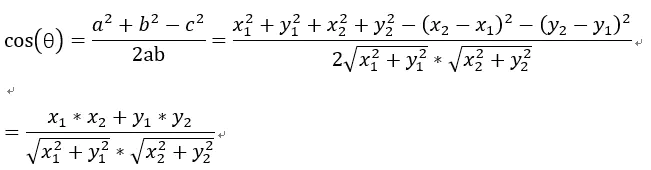
余弦的这种计算方法对n维向量也成立。假定A和B是两个n维向量,A是 [A1, A2, …, An] ,B是 [B1, B2, …, Bn] ,则A与B的夹角θ的余弦等于:
- N维向量的余弦定理
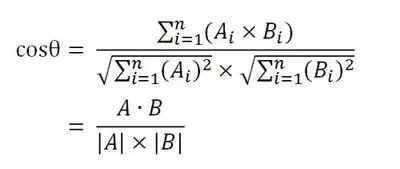
余弦相似度算法
在文本处理中,要使用余弦相似度算法,首先得将文本向量化,将词用“词向量”的方式表示可谓是将 Deep Learning 算法引入 NLP 领域的一个核心技术。自然语言处理转化为机器学习问题的第一步都是通过一种方法将这些文本数学化。其思路如下:
-
1、将两段文本(或者只是两句话)分词;
-
2、清理标点符号和一些停用词后(可选),列出两段文本中的所有出现的词;
-
3、对每一个词进行数字编码;
-
4、根据这个统一的编码,将两段文本根据词频还原为数字向量,即词频向量化;
-
5、使用余弦定理计算两个向量的余弦值,得到两段文本的相似度。
举例:
句子A:这只皮靴号码大了。那只号码合适。
句子B:这只皮靴号码不小,那只更合适。
1、中文分词:
使用分词对上面两个句子分词后,分别得到两个词集:
listA <- segment(sA);listA
[1] "这" "只" "皮靴" "号码" "大" "了" "那" "只" "号码" "合适"
listB <- segment(sB);listB
[1] "这" "只" "皮靴" "号码" "不小" "那" "只" "更" "合适"
2、列出所有词,将listA和listB放在一个set中,构成词包:
# 对listA和listB求并集
set <- union(listA,listB);set
[1] "这" "只" "皮靴" "号码" "大" "了" "那" "合适" "不小" "更"
3、使用词集分别对listA和listB计算词频。
listAcode <- rep(0,length(set))
freqA <- freq(listA)
for(i in 1:length(set)) {
for(j in 1:length(freqA$char)) {
if(set[i]==freqA$char[j]) listAcode[i] = freqA$freq[j]
}
}
> listAcode
[1] 1 2 1 2 1 1 1 1 0 0
listBcode <- rep(0,length(set))
freqB <- freq(listB)
for(i in 1:length(set)) {
for(j in 1:length(freqB$char)) {
if(set[i]==freqB$char[j]) listBcode[i] = freqB$freq[j]
}
}
> listBcode
[1] 1 2 1 1 0 0 1 1 1 1
4、对listA和listB进行整理后得到的结果如下:
listAcode = [1, 2, 1, 2, 1, 1, 1, 1, 0, 0]
listBcode = [1, 2, 1, 1, 0, 0, 1, 1, 1, 1]
5、得出两个句子的词频向量之后,就变成了计算两个向量之间夹角的余弦值,值越大相似度越高。
6、两个向量的余弦值为0.805823,接近1,说明两句话相似度很高。
计算步骤总结
两个句子的相似度计算步骤如下:
- 1.通过中文分词,把完整的句子分成独立的词集合;
- 2.求出两个词集合的并集(词包);
- 3.计算各自词集的词频并将词频向量化;
- 4.代入余弦公式就可以求出文本相似度。
TF算法总结
词频TF(Term Frequency),是一个词语在文章或句子中出现的次数。要在一篇很长的文章中寻找关键字(词),就一般的理解,一个词对文章越关键在文章中出现的次数就越多,于是我们就采用“词频”进行统计。
但是这也不是绝对的,比如“地”,“的”,“啊”等词,它们出现的次数对一篇文章的中心思想是没有帮助的,只是中文语法结构的一部分而已。这类词也被称为“停用词”,所以,在计算一篇文章的词频时,停用词是应该过滤掉的。
仅仅过滤掉停用词就能解决问题吗?也不一定。比如分析政府工作报告,“中国”这个词语必定在每篇文章中都出现很多次,但是对于每份报告的主干思想有帮助吗?对比“反腐败”、“人工智能”、“大数据”、“物联网”等词语,“中国”这个词语在文章中应该是次要的。
TF算法的优点是简单快速,结果比较符合实际情况。缺点是单纯以“词频”做衡量标准,不够全面,词性和词的出现位置等因素没有考虑到,而且有时重要的词可能出现的次数并不多。这种算法无法体现词的位置信息,位置靠前的词与位置靠后的词,都被视为重要性相同,这是不科学的。
联系到层次分析法的思想,可以赋予每个词特定的权重,给那类最常见的词赋予较小的权重,相应的较少见的词赋予较大的权重,这个权重叫做“逆文档频率”(Inverse Doucument Frequency,缩写为IDF),它的大小与一个词的常见程度成反比。而TF-IDF值就是将词频TF和逆文档频率IDF相乘,值越大,说明该词对文章的重要性越高。这就是TF-IDF算法。